Your workplace needs more WOW. Get ready for MHR's World of Work 2026
Image

Exploring Bias in AI Recruiting
04/06/2024
As AI and machine learning becomes more commonplace and goes from a theoretical nice to have to real tangible products, it becomes more and more important to look at how these systems could go wrong. An area where this is particularly prevalent is in recruitment. Here there are many areas where machine learning could be used to make improvements, but it is also somewhere we should remain vigilant for problems popping up.
Researching, I found many examples of ideas with AI used at each point in the recruiting process. From (comparatively) simple areas like skill matching in CVs, to areas I would consider more problematic such as attempting to predict which applicant will make the “best” employee.
One key theme that is prevalent throughout is the idea that by adding AI to these systems we can completely remove bias from the hiring process. This is a very dangerous idea, as while AI can help with consistency, reducing bias in one way, often bias can accidentally be reintroduced in others.
The most famous example of this is from an old Amazon hiring algorithm. They had developed a model to rate job applicants by comparing their qualities to previous good applicants. However, the historical data they used was heavily skewed towards males, creating a large amount of bias in their system and lead to the rejection of many qualified female applicants.
This is a classic case in data science of garbage data in, garbage results out. But it did get me thinking! If we could remove bias from the data we put into a model, would that prevent bias occurring in the outputs, and so solve all our problems? Probably not. If left unchecked, I believed bias could still have a chance to emerge even without the historical data problems and wanted to build a model to show this.
Modelling job applications
One use for AI is in job advertising. By releasing a number of different job adverts to a subsection of people and seeing which ads manage to attract the best overall candidates, overtime you can get a better idea of what makes a better advert. This is a process that can be automated using machine learning, using an algorithm to determine which parts of the advert made it more attractive.
I set out to create a simple model to simulate this.
In my model, a series of job adverts are shown to a random pool of potential candidates. Each candidate has a set of scored skills. Each job advert has a set of parameters for how well they attract different skillsets. This is not a 1-1 match of attraction parameter to candidate skill, but a complex function such that each parameter can affect each skill (see figure below) and attempts to simulate a candidate reading into a job ad and the hidden subtleties of language that may exist. (Note: this won't be a perfect recreation of a real-world scenario).
Each job ad is shown to a random subset of people, then scored on how well they attracted candidates that matched the job requirements. The best scoring job adverts from a round are kept and used to create more adverts, but with slight variations in their parameters. Repeating this process through a number of rounds eventually leads you to better and better adverts, until you reach an optimal version. This is the basic principle behind a genetic algorithm, a modelling method analogous to evolution, where iterative improvements are made through “survival of the fittest”. The full process is shown in the flow chart below.
Where does bias fit into this? Well, what if this complex set of attractions in your job adverts was also influenced by other factors besides a candidate’s skills. For example, what if the way you word a job advert made it appeal more to a specific gender? To simulate this, I added an extra feature to each candidate, a bias category (labelled 0, 1 or 2). Now with this, a candidate’s attraction to a given job advert will also be influenced by their bias category. Notably however, how well a candidate fits a given job and how a job advert is scored will still be independent of this category, so it should always remain unbiased…
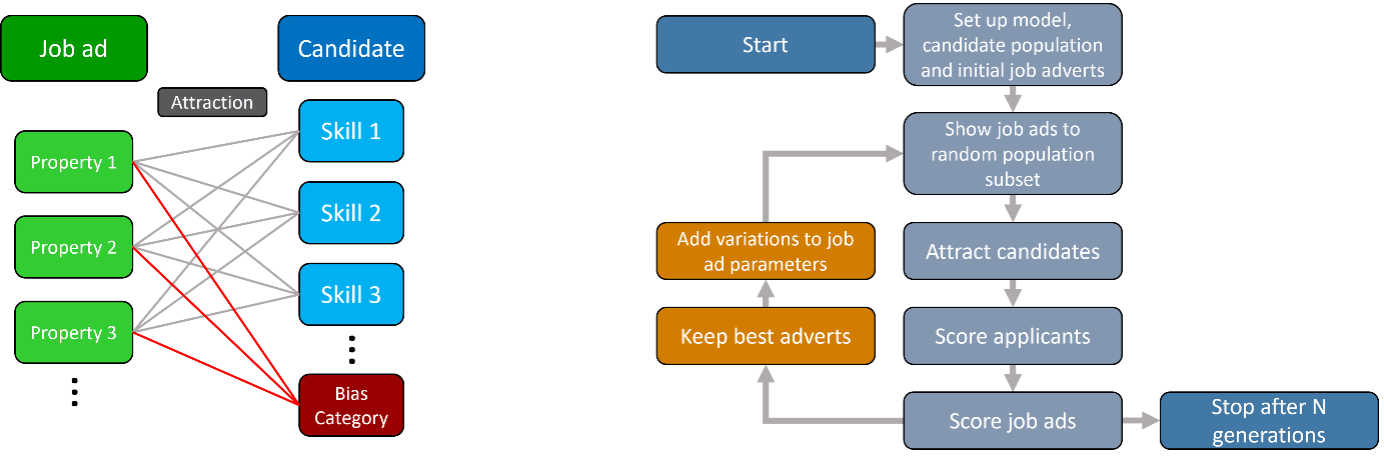
Left: How job adverts attract candidates in the model. Each ad has a number of properties, each of which will influence how well it attracts a candidate based on their skills. Additionally, each candidate has a bias category (red), and which also influences how attracted a candidate is to a particular job ad.
Right: Flow diagram for model. Orange highlighted sections show which parts correspond to the genetic algorithm.
So what happens?
With each round of the process the scoring for the best job adverts increases until it flattens out and reaches an optimal point. Small improvements could be made from there, but it’s about as good as it gets. This algorithm has produced significantly better job adverts than what we started with and so allowed us to attract the best candidates. A great success!
However, if we look at the distribution of applicants for each generation, we notice a pattern emerging. One group is consistently brought into the applicant pool at a greater rate than the others. This emerges very near the beginning of the process and remains throughout, despite the scoring system not considering this category at all. How does this happen when the model isn't tuned to consider bias when working towards a better job advert?
Early on in the process, random changes to the advert’s parameters found a combination that works better than others. This set of parameters was carried forward and inherited by all future adverts. This is by design in a genetic algorithm and is how you can make the iterative improvements you're looking for.
Incidentally, that set of parameters also happened to attract one category of candidates much better than the rest, and so this bias was also carried forward. Nothing encouraged the system to stop doing this and it worked well, so why would it change?
How do we fix this?
If we don't want these effects to occur, we need to encourage the algorithm to select for parameters that don't lead to biased results. To do this we add a penalty to the scoring system that increases the more uneven the distribution of applicants is but goes to zero when all categories are represented equally.
By adding in the bias penalty, we see a dramatic change in applicant distribution over time compared to without it. Despite initial job adverts having some bias, after only a few generations all categories are represented roughly equally among the applicant pool, and it remains this way with little deviation.
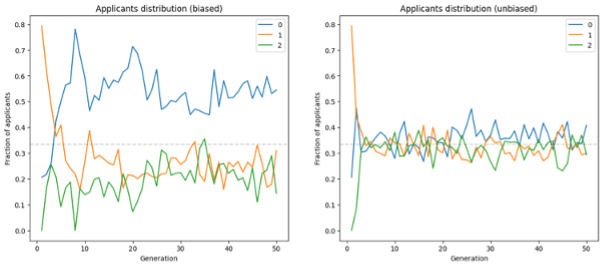
Distribution of applicants with each generation of job ads. Left shows results without bias correction, right with bias correction.
Takeaways
It's important to note that results above are only from a single run of the model. While I observed this kind of bias often, it doesn't occur every time, and is highly dependent on the initial set up. When it did occur however, the distribution of applicants was often extreme and would rarely correct itself on its own.
This is a simple model with a large number of issues, but it manages to highlight the importance of not blindly relying on AI to fix everything. It can help with certain aspects but still needs to be monitored in case unforeseen problems emerge. In this instance, a small adjustment could be made to fix the problem, but this may not always be the case or the problem itself may not be immediately apparent.
Overall, I hope this work further emphasises the need to keep humans in the loop for any AI system you introduce and ensure that such systems are properly monitored to prevent such problems from emerging.